
Knowing that the voice on the other end of the phone is human will be getting a bit more difficult. Google’s Deepmind, who had previously published a new method for an AI kill switch, has announced their latest deep neural network project. In a blog post on the Deepmind site, Wavenet is a new Text to Speech (TTS) model that generates raw audio files.
Text to speech programs have gained in popularity as the “voice” of the digital assistant in our phones and computers. Before Wavenet, concatenative TTS was considered one of the closest models to mimicking a human voice on the mean opinion scores (MOS) scale.
Concatenative TTS relies on using pre recorded spoken samples and then arranging them to produce the needed sounds. Even though this was the most natural sounding method at the time, it is not without its limitations. Individual sounds are generated independently and can lead to unnatural sounding word. Also, It requires recording new samples if an adjustment for emphasis or emotion is needed.
These limitations lead to the development of parametric TTS where the parameters of the samples are contained within the model and adjustments are easier to make. This newer model provides greater flexibility over the previous model but produced a less natural voice (below).
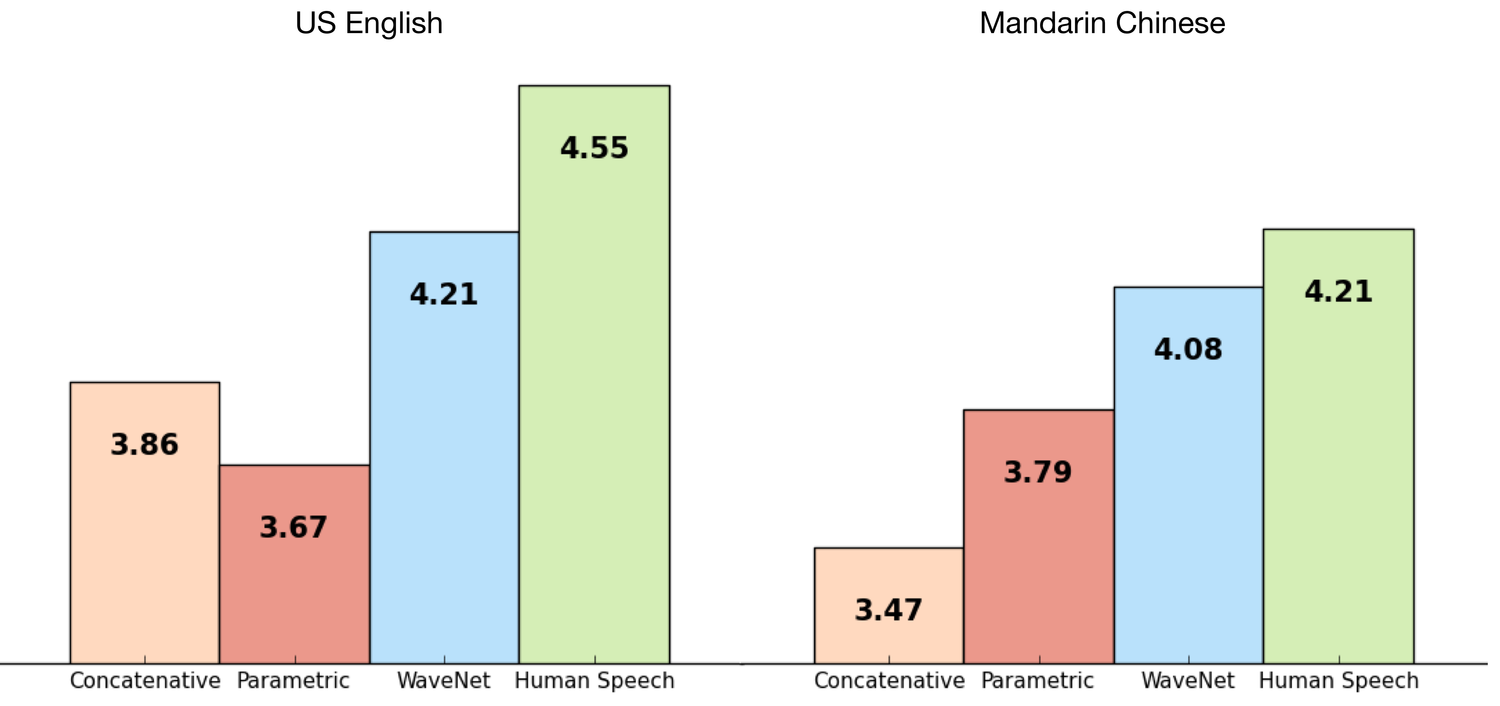
The breakthrough with Wavenet comes from the concept of using data from the entire input when generating the sound clip. This allows for the neural network to generate a raw audio waveform that sounds more natural. Optionally, in order to even closer model human speech, they can inject the sound of a person breathing or other audible mouth movements into the waveform.

And here are some samples of the three models
As with any deep neural network, the models require extensive training. According to Deepmind, the Wavenet model uses 44 hours of audio from 109 different speakers. This allows them to produce the same audio in different voices without the need for retraining.
With the advancements in voice recognition combined with a near human voice output, you might just be talking to a neural network the next time you press 4 to speak to a representative.









{kind=link}